Piece of Mind
之前的post不支持Markdown输入,找时间再把内容搬过来
🌘
2025-02-25 22:58:35 Monday
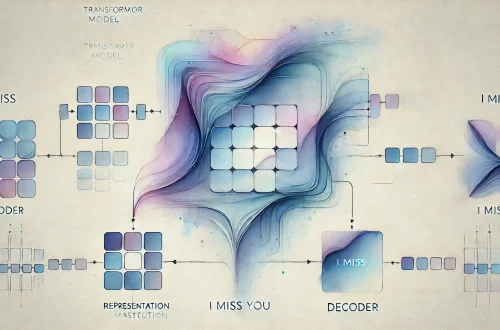
RAG 检索增强技术
Retrieval-Augmented Generation
当用户向 LLM 提问时,AI 模型会将查询发送给外部知识库,将检索到的信息与输入结合,生成更准确的回答。
流程:
| 阶段 | 步骤 | 描述 |
|---|---|---|
| 输入处理 | 切分 | 将输入文本切分为句子、短语或关键词。 |
| 编码 | 使用编码器(如BERT)将切分后的文本转换为向量表示。 | |
| 检索阶段 | 向量检索 | 将编码后的输入向量与知识库中的文档向量进行相似度计算,通常使用余弦相似度。 |
| Top-K检索 | 选择相似度最高的K个文档或段落作为候选。 | |
| 生成阶段 | 上下文编码 | 将检索到的文档与原始输入结合,再次编码为上下文向量。 |
| 解码生成 | 使用解码器(如GPT)根据上下文向量生成最终输出。 |
Note: 外部知识库只是额外inputs,所以不需要进行训练。但在高级实现中,检索模块和生成模块可以联合训练。
作为一种技术,它一定有门槛:
| 门槛 | 关键点 | 描述 |
|---|---|---|
| 检索系统构建 | 高效检索大规模知识库 | 需要支持快速检索大规模外部知识库(如维基百科、专业数据库)。 |
| 快速向量相似度计算 | 检索系统需支持快速向量相似度计算(如使用FAISS、Annoy等近似最近邻搜索工具)。 | |
| 模型集成 | 检索与生成模型结合 | 需要将检索模块与生成模型(如GPT、T5等)无缝结合。 |
| 输入输出对齐 | 检索和生成模块的输入输出需对齐,确保信息传递一致。 | |
| 计算资源 | 高性能硬件支持 | 检索和生成过程需要大量计算资源,尤其是处理大规模知识库时。 |
| GPU/TPU支持 | 需要高性能硬件(如GPU/TPU)支持。 |
🌒
2025-06-14 Saturday
RAG的7个核心概念
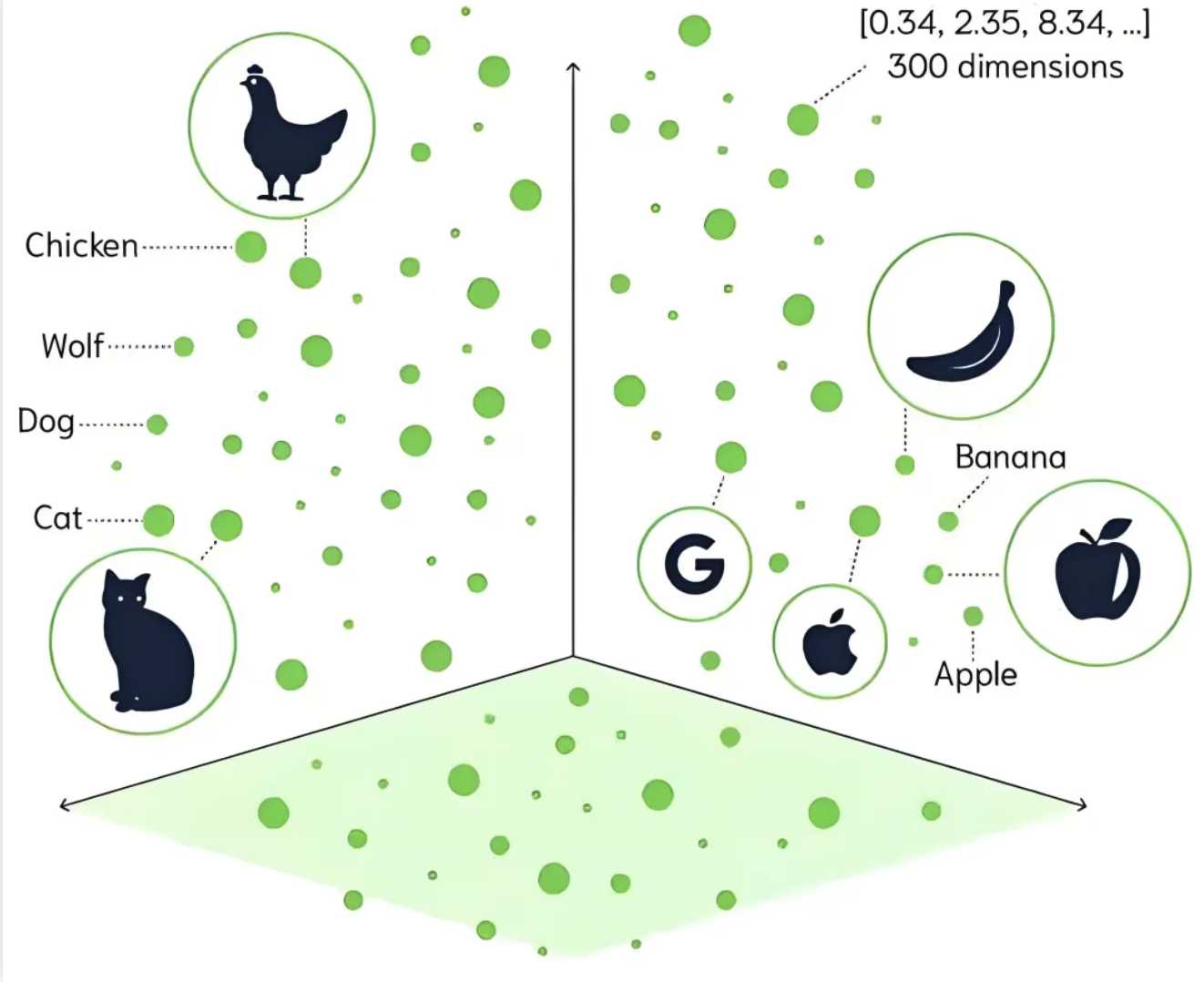
1. 向量数据库:
将知识转化为向量(也就是embedding),依靠inputs与知识之间的相似性而不是传统数据库的关键词匹配,从而大大降低对查询精确度的要求,并且能够处理较长的输入信息。这是语义检索与关键词检索之间的核心差异。
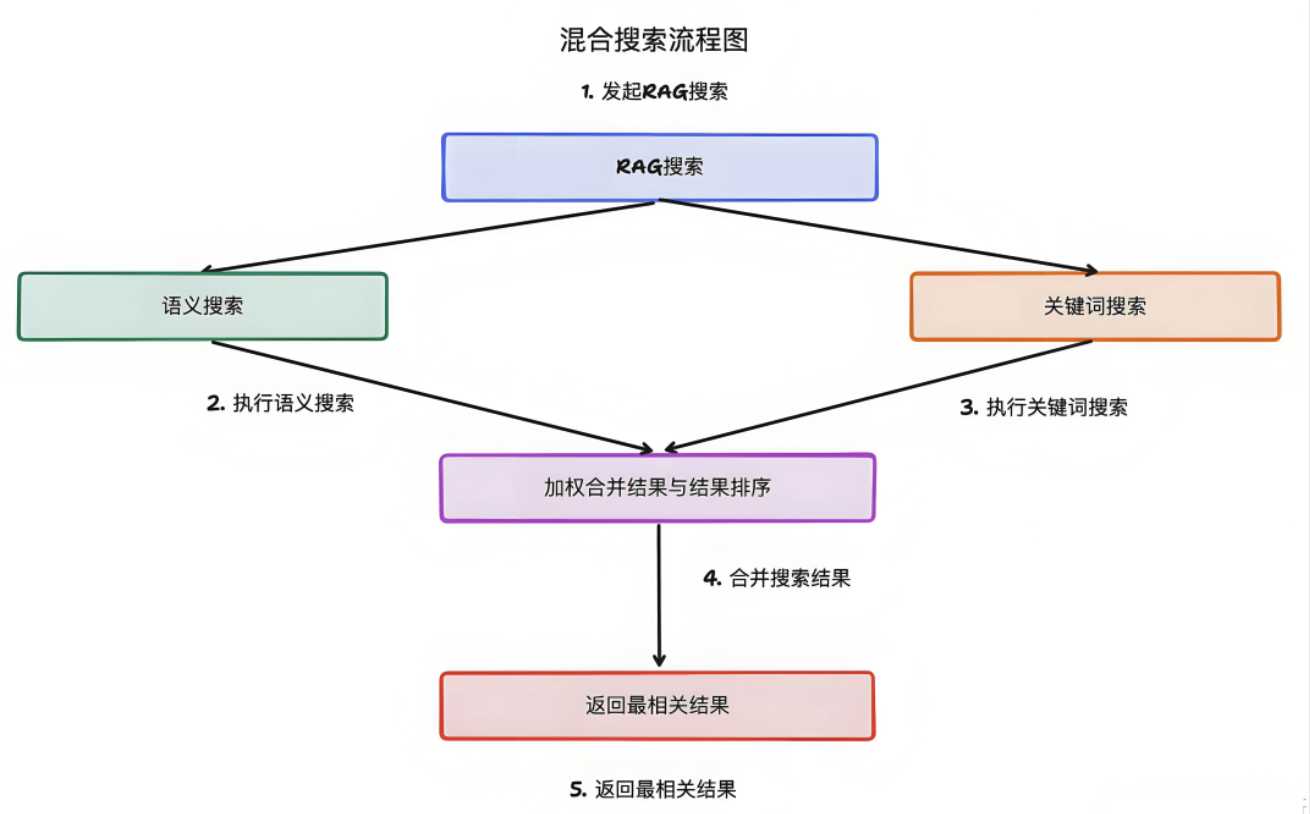
2. 混合检索
但是面对超大数据量,语义检索的速度和效率不如传统的关键词检索,而且在某些特定的场景下,对检索的精确性的要求很高(比如法律条文,案例等),以及需要特定词块结合(无线、蓝牙适用语义检索,“无线蓝牙”则要求关键词精确匹配)。所以RAG会同时使用关键词检索和语义检索,从而尽可能提升检索体验。
3. 分块,嵌入,与索引
RAG在存储知识时为了更高效地检索和管理,通常将原始文档按照一定的规则(如固定长度或者语义单元)进行分块,比如按章节,这样查找故事情节就比较方便快捷。分块以后将每一个快转化为向量进行存储,这样再进行一次嵌入(embedding)。向量存储在一个高效的检索结构中,以便快速进行相似性计算和检索,这就是索引。
4. 重排序(re-rank)
当RAG从数据库中检索出多个内容时,需要选取相关性最大的内容作为回答的inputs。比如电商平台根据用户需求初步筛选出一批商品后就通过重排序,根据用户的实时行为、偏好历史等等,对商品进行重新排序。
5. 上下文融合
上下文融合是指 RAG 将从多个来源检索到的知识进行整合,以便为大模型提供更全面、连贯的输入内容,这样大模型的回答才能条理清晰、内容完整。比如在智能客服场景中,用户咨询:“我刚收到的商品有点瑕疵,我可以申请退货吗?”RAG 需要从多个来源检索信息,比如用户的订单信息、退货政策等,再把这些内容整理成统一的内容,以便大模型能够基于内容生成高质量的回答。
6. 准确率和召回率
准确率是衡量检索质量最重要的指标之一:准确率(Precision)是指在 RAG 检索到的内容中,与用户问题真正相关的内容的比例。例如,在一个问答系统中,检索到 10 条知识,其中有 8 条与用户问题高度相关,那么准确率就是 80%。
所谓召回率(Recall),是指与用户问题相关的所有知识中,被成功检索到的比例。例如,知识库中有 20 条与用户问题相关的知识,检索到 12 条,那么召回率就是 60%。
F1 值的计算公式是:F1= 2(精确率*召回率)/(精确率+召回率),可以用来衡量二者的平衡,当二者中任何一个很低的时候F1的值都会相应降低,所以F1高的时候,两个比例一定不会是失衡的。
7. 知识图谱
利用知识图谱建立实体之间的关系,通过图谱,RAG能捕捉到实体间复杂的关系,还能根据已有的实体关系进行推理和扩展,发现更多潜在的相关信息。
最后,一个 RAG 系统的运行可能包含以下步骤:
1、向量数据库提供知识存储的基础设施
2、对内容进行分块、嵌入和索引,以方便检索
3、再通过知识图谱建立相关实体的关系,从而提高检索和生成的准确度
4、当用户查询时,通过混合检索、知识图谱等方式检索内容
5、然后把检索出来的内容进行重排序,选出最相关的内容
6、把选出的内容进行上下文融合,提供给大模型生成回答内容
7、最后,通过F1 值对 RAG 系统的准确率和召回率进行综合评估
 |
 |
|---|---|
🌒
2025-03-04 00:04:29 Tuesday
存储器
- DRAM(动态随机存取存储器):
- 类型:易失性存储器,断电后数据丢失。
- 用途:主要用于系统内存(如电脑的RAM),需要频繁刷新以保持数据。
- 特点:读写速度快(数十GS/s),适合临时存储和高速访问。容量较小(16GB/32GB),价格较高。
- 闪存(Flash Memory)
技术原理:闪存是一种非易失性存储器,基于NAND或NOR技术,断电后数据不会丢失。
- NAND闪存:主要用于大容量存储(如SSD、USB闪存、存储卡),TB级别
- NOR闪存:用于代码存储(如嵌入式系统的固件)。
- 特征:
- 读写速度较DRAM慢(最高数GB/s),但比传统硬盘快。
- 容量大,适合长期存储。
- 擦写次数有限,寿命受写入次数影响。
行业壁垒:
- 技术壁垒:
- DRAM芯片工艺节点是最关键的(国际领先厂商已经进入10nm)
- NAND:堆叠层数,层数越多,存储密度越高,单位面积的容量越大。增加层数是提升NAND闪存容量的主要方式之一。国际领先水平是200层+,国内领先水平是128层。
- 产业链整合:在存储器的设计、制造、封装和测试等环节具有完整的垂直整合能力。
| 参数 | 定义 | 影响 | 现状 |
|---|---|---|---|
| 工艺节点 | 制造工艺的尺寸(nm) | 节点越小,性能越高,功耗越低,成本越低 | DRAM:10nm级;NAND:100层以上3D NAND |
| 层数 | 3D NAND中垂直堆叠的存储单元层数 | 层数越多,容量越大 | 国际:200层以上;国内:128层 |
| 存储容量 | 存储器能存储的数据量(GB/TB) | 容量越大,存储数据越多 | DRAM:单颗16Gb+;NAND:单颗1Tb+ |
| 读写速度 | 读取或写入数据的速度(MB/s或GB/s) | 速度越快,性能越好 | DRAM:几十GB/s;NAND:几GB/s |
| 延迟 | 从请求到数据传输的时间(ns或μs) | 延迟越低,响应越快 | DRAM:几十纳秒;NAND:几十微秒到几毫秒 |
| 功耗 | 工作状态下的能耗(W) | 功耗越低,能效越高 | DRAM:较低;NAND:更低 |
| 耐久性 | NAND闪存能承受的编程/擦除循环次数(P/E Cycles) | 耐久性越高,寿命越长 | SLC:10万次;QLC:1000次 |
| 接口类型 | 存储器与外部设备通信的接口标准 | 影响数据传输速度 | DRAM:DDR4/DDR5;NAND:SATA/PCIe(NVMe) |
| 封装技术 | 芯片的封装形式(如TSV、CSP) | 影响尺寸、散热和集成度 | 国际:3D封装(如HBM、Chiplet) |
| 错误校正技术 | 用于检测和纠正数据错误的技术(ECC) | 提高可靠性和数据完整性 | 高端DRAM和NAND普遍支持 |
HBM又是什么?
| 特性 | DDR | GDDR | HBM |
|---|---|---|---|
| 设计目标 | 低延迟、大容量 | 高带宽、高频率 | 超高带宽、低功耗 |
| 用途 | 系统内存 | 图形内存 | 高性能计算、AI、数据中心 |
| 带宽 | 较低(DDR5约50-100 GB/s) | 较高(GDDR6X可达112 GB/s) | 极高(HBM3可达819 GB/s) |
| 延迟 | 较低 | 较高 | 低 |
| 容量 | 较大(单条128GB+) | 适中(单颗16Gb,多颗组合) | 适中(单颗24GB+) |
| 功耗 | 较低 | 较高 | 低 |
| 成本 | 较低 | 中等 | 高 |
| 应用场景 | 通用计算、消费电子 | 图形处理、AI加速 | 高性能计算、AI、数据中心 |
:full_moon:
2025-06-13 Friday
显存
关键区别在于读写速度远高于普通内存
| 项目 | 显存(VRAM) | 系统内存(RAM) | 闪存(Flash Memory) |
|---|---|---|---|
| 技术类型 | DRAM家族(但封装特殊) | 标准DRAM | NAND Flash |
| 是否易失性 | 易失性 | 易失性 | 非易失性 |
| 常见技术 | GDDR、HBM | DDR4、DDR5 | NAND(3D NAND) |
| 主要用途 | GPU运算缓存 | CPU运算缓存 | 持久化数据存储(SSD、手机存储) |
| 访问速度 | 超高速(几百 GB/s\~几 TB/s) | 高速(几十 GB/s) | 很慢(MB/s\~GB/s) |
| 典型容量 | 8GB\~192GB | 8GB\~1TB | 256GB\~10TB |
实现高速读写的路径:
1)单次搬运数据量更高:更宽的数据总线(256bit或更宽);
2) 每秒钟的传输次数极高:更高的I/O频率(20~24Gbps/pin) + 为并行计算进行优化架构(并行通道更多);
3) 更短的数据传输距离:HBM采用3D TSV采用硅中介层直接连接在GPU/ASIC旁边(把多层 DRAM 直接往上叠(通常4层、8层、12层、甚至24层),每层之间用 TSV 通孔直接导通,减少横向布线,缩短信号路径,带宽暴涨
当然必定需要付出一定代价:
1)技术壁垒(TSV堆叠+封装难度高)+ 良率压力;
2)功耗高(高速I/O) + 散热挑战(贴近GPU);
3)高成本:HBM采用硅中介层(interposer),封装极其昂贵
- 产业链:
设计:HBM规范(JEDEC)
制造:SK Hynix / Samsung / Micron
封装:TSMC (CoWoS), ASE, Amkor
设备:Applied Materials, TEL
封装材料:Ajinomoto、Shinko
:full_moon:
2025-06-15 Sunday
基础的公有云服务
- 计算资源:
裸金属服务器:直接租用物理服务器硬件,完全不经过虚拟化层,客户独占硬件资源。允许客户自定义底层操作系统、驱动、中间件。典型应用是核心数据库、高性能金融交易系统(需要高安全性低延迟)、安全性要求高的政企、SAP/Oracle大型企业应用。
|
弹性云服务器(IaaS):底层技术是利用虚拟化技术(VMware)在物理服务器上动态划分出多个虚拟机,客户按需租用算力资源,随用随付,随时扩展/缩减。应用场景主要是轻量应用、弹性电商系统和基础的后台服务器等。
|
**GPU弹性计算:在弹性云服务器基础上,附加 GPU 卡,实现并行加速计算能力。
|
容器引擎与自动伸缩服务:容器引擎:通过 Kubernetes (K8s) 或 Docker 管理应用容器,提升应用的部署、管理、扩展效率;自动伸缩:根据业务负载自动增加/减少计算资源(如服务器数量)
典型应用是电商秒杀活动 - 存储与分发:
– 对象存储:非结构化数据的存储方式, 依靠object id读取,每个对象有唯一的URL或者key
– 文件存储与缓存:供与操作系统一致的文件访问接口(支持挂载路径、读写权限等)
– 内容分发网络(CDN):将静态内容(图片、视频、脚本)缓存到离用户更近的边缘节点,从而加快访问速度、减轻源站(orgin)压力。CDN 是云服务厂商的基础竞争门槛之一。
– 源站:原始数据服务器
– 边缘节点:edge node – 部署在各地的数据缓存服务器
– DNS调度:根据用户位置自动路由到最近节点
– 负载均衡(SLB)将来自用户的大量请求按规则分发到多台后端服务器,提高系统的并发能力和容灾能力。
| 模块 | 商业价值 | 技术壁垒 |
|---|---|---|
| 对象存储 | 粘性强、容量大 | 数据安全性、兼容协议、高可用 |
| Redis缓存 | 高频请求入口 | 单点故障控制、容器部署 |
| CDN | 加速体验 | 布点成本、调度算法 |
| SLB | 高可用基础设施 | 自动化扩缩容能力、服务发现 |
- 数据库服务:关系型数据库,分布式缓存,NoSQL服务
- 网络与安全:
虚拟私有网络
安全产品
高级应用与行业解决方案
垂直行业云:针对游戏、视频、政务、金融、医疗等行业定制云解决方案,提供专业服务支持
3. 边缘与混合云能力
混合云存储:
:full_moon:
2025-06-16 Monday
服务器vs.算力
| 模块 | 主要部件 | 功能 |
|---|---|---|
| 计算单元 | CPU、GPU、ASIC、FPGA | 提供算力,完成数据计算 |
| 内存单元 | DDR5、HBM、高带宽内存 | 数据缓存与高速读写 |
| 存储单元 | SSD、HDD、NVMe | 持久性数据存储 |
| 网络单元 | NIC、Infiniband、以太网 | 服务器之间及服务器对外通信 |
| 供电单元 | PSU(电源供应单元) | 提供稳定电力 |
| 散热单元 | 风冷、液冷、CDU、冷板 | 保持服务器正常工作温度 |
| 主板 & 总线 | PCIe、CXL | 连接和协调各模块数据传输 |
| 管理模块 | BMC、IPMI | 远程管理、监控服务器状态 |
物理层(硬件):服务器
↳ 计算单元:CPU、GPU、FPGA、ASIC
↳ 算力输出(业务层面):FLOPS、推理吞吐、训练速度、QPS、Token/sec
↳ 商业化售卖单位:vCPU套餐、GPU租用时长、推理API调用次数
通用服务器/AI服务器/超大规模定制服务器
| 模块 | 通用服务器(General Purpose Server) | AI服务器(AI Training Server) | 超大规模定制服务器(Hyperscale Custom Server) |
|---|---|---|---|
| 应用场景 | Web、数据库、ERP、虚拟化、轻量计算 | 大模型训练、推理、深度学习、科学计算 | 云厂商自研,专为云工作负载优化 |
| CPU | 1-2颗 x86(Intel Xeon / AMD EPYC) | 1-2颗高端CPU | ARM/x86定制化、自研芯片(如Amazon Graviton) |
| GPU/加速卡 | 通常没有或少量(低端GPU) | 4-8颗H100/A100/MI300/HGX架构 | 依需求定制化扩展加速模块 |
| 内存 | DDR4/DDR5 (128\~512GB) | DDR5+HBM (512GB\~1TB+) | 大容量DDR5/HBM,CXL扩展 |
| 存储 | SSD+HDD混合存储 | 高速NVMe SSD(TB\~PB级) | 定制化高IOPS全闪存 |
| 网络 | 1-10Gb以太网 | 200Gb InfiniBand、RoCE | 高速自研网络 (400G/800G Infiniband、光模块整合) |
| 散热 | 风冷 | 液冷(CDU/冷板/浸没式) | 液冷、混合冷却系统 |
| 功耗 | 500W\~1000W | 3kW\~10kW+ | 大部分为5kW\~15kW高密度架构 |
| 管理 | 标准BMC/IPMI | 高级远程管理 | 全栈自研调度与运维平台 |
| 主板 | 商用标准ATX、OEM平台 | 高速PCIe 5.0/6.0、高带宽总线 | 定制化总线架构 |
| 代表厂商 | Dell、HPE、浪潮、联想 | NVIDIA DGX、Supermicro、华为Atlas、浪潮NF系列 | Amazon、Google、Microsoft、阿里、腾讯、字节、百度 |
:waning_gibbous_moon:
2025-06-19 00:19:55 Thursday
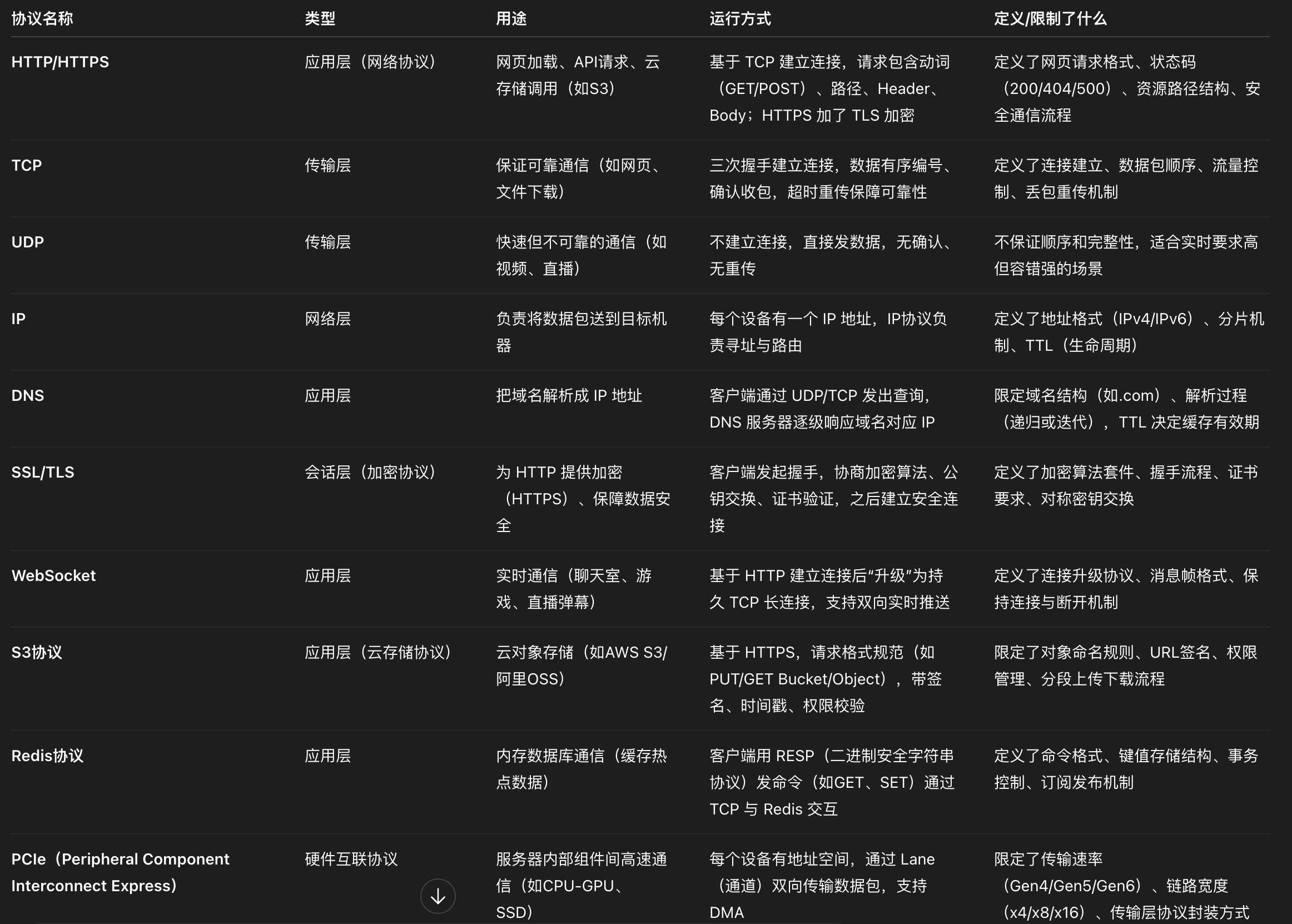
协议
- 定义:协议(Protocol)就是一套“通信规则”,决定了数据怎么传、怎么接、怎么解释。
- 协议在物理层面上的类别:
┌────────────────────────────┐
│ 用户请求 / 应用协议(如HTTP、S3) │ ← 逻辑层(你在写的代码、发的请求)
├────────────────────────────┤
│ 数据格式协议(TCP/IP、TLS、DNS) │← 绝对数据该发到哪台机器(IP)
├────────────────────────────┤
│ 帧结构与地址协议(Ethernet / Wi-Fi) │← 定比bit怎么打包成帧附上MAC地址
├────────────────────────────┤
│ 电信号调制协议(PCIe / USB / 光通信) │ ← 接近物理层:电信号怎么传
├────────────────────────────┤
│ 实际物理介质(电缆、电路板、光纤) │ ← 完全物理层
└────────────────────────────┘ - 协议按用途分类
遇到的需求 看什么协议 访问网页、调API HTTP / HTTPS / DNS 远程登录服务器 SSH 上传/下载文件 FTP / S3 / NFS / SMB AI数据缓存 Redis / NFS 云存储 S3协议 / OSS / COS 高速SSD NVMe / PCIe GPU互联 PCIe / InfiniBand 多设备数据传输 TCP / UDP / WebSocket 工业/汽车通信 Modbus / CAN 外设传输 USB协议
:waning_gibbous_moon:
2025-06-19 23:43:08 Thursday
网络的结构
- MAC地址(Media Access Control Address)
- 是每个网络设备(如网卡、Wi-Fi模块)在出厂时烧录的唯一硬件地址,用于在局域网(LAN)中识别设备。一共 48 位(6字节),常前 3 个字节表示厂商(例如 Intel、Realtek)后 3 个字节是设备序列号
- 以太网帧(Ethernet Frame):
- 局域网中用于传输数据(封装和投递)中的容器,源 MAC、目的 MAC、IP 数据包,以及用于校验的 CRC 校验码(保证数据完整)等,是将 IP 包封装后,在网络上“真正传输”的单位。
- IP 地址(Internet Protocol Address,互联网协议地址)是分配给每台连接到互联网的设备的唯一识别号码,就像是设备在网络中的“门牌号”。
- 当访问一个网站时,DNS 把域名解析为 IP 地址,然后你的设备就根据这个 IP 地址,找到对应的网站服务器
┌─────────────┐
│ 应用层 │ → 浏览器发送请求
└─────────────┘
↓
┌─────────────┐
│No.4传输层 TCP│ → 加上端口号、序列号
└─────────────┘
↓
┌─────────────┐
│No.3网络层 IP │ → 加上 IP 地址
└─────────────┘
↓
┌─────────────┐
│ No.2Ethernet│ → 加上 MAC 地址
└─────────────┘
↓ 物理信道(电波或者网线)
┌─────────────┐
│ No.1 物理层 │ → 转为电/光信号
└─────────────┘
↓
┌─────────────┐
│ 接受端网卡 │ → 检查目的MAC是否是自己 – 是则拆帧>还原IP包>向上传递给系统,不是则丢弃
└─────────────┘
2025-09-04 23:57:25 Thursday
深度学习框架(Deep Learning Framework)是一套 软件工具和库,它把底层复杂的数学计算(矩阵运算、反向传播、梯度下降、GPU并行计算等)封装起来,提供 更高层次的接口,让研究人员和开发者更容易 搭建、训练和部署神经网络。
可以视作“做深度学习的操作系统”,你不需要自己写线性代数运算(不需要自己写矩阵运算,手动推导梯度),就能专注在 设计模型结构和算法逻辑,可以视作“做深度学习的操作系统”,你不需要自己写线性代数运算,就能专注在 设计模型结构和算法逻辑上。
| 功能 | 解释 | 举例 |
|---|---|---|
| 张量计算 (Tensor Computation) | 提供类似 NumPy 的矩阵/向量运算,但支持 GPU/TPU 加速 | torch.Tensor、tf.Tensor |
| 自动微分 (Auto-differentiation) | 自动计算梯度,避免人工推导 | PyTorch 的 autograd、TF 的 GradientTape |
| 模型搭建 (Model Building) | 提供神经网络层、激活函数、损失函数的模块化接口 | torch.nn.Linear、tf.keras.layers.Dense |
| 训练与优化 (Training & Optimization) | 提供常见优化器和训练循环工具 | SGD、Adam 等 |
| 部署与推理 (Deployment) | 模型导出、跨平台部署 | TensorFlow Lite、TorchScript、ONNX |
Question Hub
CDN服务为什么是云服务厂商的竞争门槛?
Discover more from Christina's World
Subscribe to get the latest posts sent to your email.
You May Also Like